
- The photos are availble now!
- Important: Registration START! Deadline: January 16th, 2015 (PST)
- The hotel reservation at group rate for Anhheim Marriott is available now. Please check "Hotel Information". Special rate cut-off on Jan. 20
- We are sorry that the registration is not ready due to IEEE account delay. It should be ready soon and we will extend the deadline.
- (Correction on email address) Visa Instructions
- Important: Camera-ready Submissions START! Deadline: December 31st, 2014 (PST)
- The conference date is shift to an earlier time due to the hotel contract issue.
- October 31st, 2014 (midnight, PST): Regular/Short/Poster/Demo Paper Submission (Extended)
- October 31st, 2014 (midnight, PST): Industry Paper Submission (Extended)
Ninth IEEE International Conference on Semantic Computing
February 7-9, 2015
Anhheim Marriott
Anaheim, California, USA
http://www.ieee-icsc.org/
Semantic Computing (SC) is Computing based on Semantics (“meaning”, "context", “intention”). It addresses all types of resource including data, document, tool, device, process and people. The scope of SC includes analytics, semantics description languages and integration, interfaces, and its applications in biomed, IoT, cloud computing, SDN, wearable computing, context awareness, mobile computing, search engines, question answering, big data, multimedia, services, etc.
The technical program of the Ninth IEEE International Conference on Semantic Computing (ICSC 2015) will include workshops, invited keynotes, paper presentations, panel discussions, demonstrations, and more. Submissions of high-quality papers describing mature results or ongoing work are invited.
SUBMISSIONS
Regular Papers, Short Papers, and Industry Papers
Authors are invited to submit an 8-page (regular), 4-page (short), or 6-page (industry) technical paper manuscript in double-column IEEE format following the guidelines available on the ICSC20105 web page.
Demonstration Papers and Posters
Authors are invited to submit an 2-page (demonstration or poster) technical paper manuscript in double-column IEEE format following the guidelines available on the ICSC2015 web page.
Workshops Proposals
The organizing committee invites proposals for workshops to be held in conjunction with the conference. These will focus on specific topics of the main conference. More information is available on the ICSC2015 web page. The Conference Proceedings will be published by IEEE Computer Society Press. Distinguished quality papers presented at the conference will be selected for publication in internationally renowned journals.
AREAS OF INTEREST INCLUDE (but are not limited to):
Analytics (from contents to semantics)
- Natural language processing
- Image and video analysis
- Audio, music and speech analysis
- Structured data
Description and Integration
- Semantics description languages
- Ontology integration
- Interoperability
Semantic Interfaces
- Natural
- Multimodal
Use of Semantics in IT
- Multimedia
- IoT
- Big data
- Deep learning
- Cloud computing
- SDN
- Wearable computing
- Mobile computing
- Search engines
- Question answering
- Web services
- Security and privacy
Use of Semantics in Interdisciplinary Applications
- Biomedicine
- Healthcare
- Manufacturing
- Engineering
- Education
- Finance
- Entertainment
- Business
- Science
- Humanity
- August 15th, 2014: Workshop Proposals
- October 31st, 2014 (midnight, PST): Regular/Short/Poster/Demo Paper Submission
- October 31st, 2014 (midnight, PST): Industry Paper Submission
- December 8th, 2014: Notification Date
- December 31th, 2014: Camera-Ready Submission
- January 16th, 2015: Registration (Extended)
- January 13th,2015: Preliminary Program Available
- February 7th-9th, 2015: Conference
Organizing Committee
General Co-Chairs
Ching-Yung Lin, IBM T. J. Watson Research Center, USA
Abha Moitra, GE Research, USA
Mei-Ling Shyu, University of Miami, USA
Program Co-Chairs
Mohan S. Kankanhalli, National University of Singapore
Tao Li, Florida International University, USA
Wei Wang, University of California, Los Angeles, USA
Workshop Co-Chairs
Oscar Au, Hong Kong University of Science and Technology (HKUST), China
Yu Cao, The University of Massachusetts Lowell, USA
Min Chen, University of Washington Bothell, USA
Zifang Huang, Western Union Digital, USA
Robert Mertens, HSW University of Applied Sciences, Hamelin, Germany
Giovanni Pilato, Italian National Research Council, Italy
Nadine Steinmetz, Business Software Solutions GmbH, Germany
Industry Co-Chairs
Sabrina Lin, IBM T. J. Watson Research Center, USA
Hamid Mousavi, University of California, Los Angeles, USA
Nick Pendar, Skytree Inc., USA
Panel Co-Chairs
Brian Harrington, University of Toronto, Canada
William Hsu, University of California, Los Angeles, USA
David Ostrowski, Ford, USA
Demo Co-Chairs
Jeffrey Abbott, Semantic Computing Consortium, USA
Lin Lin, American National Standards Institute, USA
Anne Hunt, Otto, Inc., USA
Tutorial Chair
Yanfang Ye, West Virginia University, USA
Publicity Co-Chairs
Ramazan Savas Aygun, University of Alabama in Huntsville, USA
Chao Chen, Capital One Bank, USA
Keith Chan, Hong Kong Polytech University
Dianting Liu, University of Miami, USA
Wolfgang Hurst, Utrecht University, The Netherlands
Yonghong Tian, Peking University, China
Qiusha Zhu, Senzari Inc., USA
Roger Zimmermann, National University of Singapore, Singapore
Publication Co-Chairs
Min-Yuh Day, Tamkang University, Taiwan, ROC
Jennifer Kim, University of California, Irvine, USA
Tao Meng, University of Miami, USA
Best Paper Award Co-Chairs
Homer Chen, National Taiwan University, Taiwan, R.O.C.
Gerald Friedland, ICSC Berkeley, USA
Finance and Local Arrangement Co-Chairs
Taehyung Wang, California State University Northridge, USA
Chengcui Zhang, University of Alabama at Birmingham, USA
Registration Co-Chair
Wei-Bang Chen, Virginia State University, USA
Shao-Ting Wang, University of California, Irvine, USA
Web Chair
Shao-Ting Wang, University of California, Irvine, USA
------------- Accepted Workshops ---------------------
IEEE International Workshop on Semantic Multimedia (ICSC-SMM’15)
International Workshop on Future Information Security, Privacy and Forensics for Complex systems (ICSE-FINSEC'15)
Tutorial and Workshop on Semantic Computing with Big Data (TWSCBD 2015)
CALL FOR WORKSHOP PROPOSALS
IEEE ICSC 2015: The Ninth IEEE International Conference on Semantic Computing
February 7th - 9th, 2015, Anaheim, California, USA
The IEEE ICSC 2015 organizing committee invites proposals for workshops to be held in conjunction with the conference.
The workshops will focus on specific topics of the main conference. The organizer(s) of approved workshops are responsible for advertising the workshop, distributing the call for papers, gathering submissions, and conducting the paper review process.
Any general questions regarding ICSC 2015 Workshops and workshop proposals should be directed to Dr. Giovanni Pilato at icsc2015ws@pa.icar.cnr.it
Please add [ICSC2015-WS-Proposal] as subject.
Important Dates:
September 15, 2014: Workshop Proposals due
-------------------------------------------------------------
Note:
1. Every paper accepted for publication in the Proceedings of ICSC 2015 MUST be presented during the conference.
2. Every paper accepted for ICSC 2015 MUST have attached to it at least one registration at the full member/nonmember rate. Thus, for a paper for which all authors are students, one student author will be required to register at the full registration rate.
Dr. Joseph Barr, Chief Analytics Officer, HomeUnion, Irvine, California.
joseph@homeunion.com
ICSC-REA'15 is the first International Workshop on real estate analytics. The aim of the workshop is to promote the state-of-the-art researches regarding real estate analytics. The ICSC-REA'15 workshop provides a forum for researchers, engineers, and scientists in affiliated disciplines to present their latest research progress, exchange brilliant ideas/thoughts, and explore new research directions. We continue seeking high quality research contributions and encouraging significant work that addresses the major challenges in the real estate analytics domain. Topics of interest include but are not limited to practical areas that span a variety of aspects of real estate analytics including
• SFH price trends
• SFH pricing
• The rental space
• Real Estate Investment Trusts (REITs)
• Single-family rental (SFR)
• Population dynamics and real estate
• Demographics and impact on real estate
• The commercial building space
• RE trending with social media
• Public policy impacts on SFH
• Mortgage analytics
• Macroeconomics and RE
• Neighborhoods – RE analytics with micro location
• RE analytics methodology: Spatial-temporal statistics with missing values, time-series, missing value treatments
• RE-specific economic indicators
The conference will take place at the University Center of CMU – west of the stadium
Campus Map
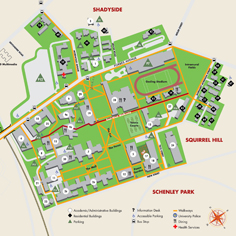
Travel:
http://www.cmu.edu/about/visit/directions-parking.shtml
Pittsburgh Airport Flyer:
http://www.portauthority.org/PAAC/tabid/241/default.aspx
keynote
by Ramesh Jain,
University of California, Irvine
Abstract
Speaker Bio

keynote
by Charles Elkan,
University of California, San Diego
Abstract
Speaker Bio
keynote
by David Newman,
Wells Fargo
Abstract
Speaker Bio

keynote

by Ramesh Jain,
Department of Computer Science
University of California, Irvine
jain@ics.uci.edu
The twenty-first century brought a new revolution in information technology. Capturing, storing, and sharing photos have now become easier than corresponding operations using text. This is a major change in the way information gets created, communicated, and consumed. According to estimates the number of photos captured in 2014 is 900 Billion!
A photo represents a moment. The moment is usually related to an event at which more photos may have been captured. Each photo is taken at a place, with some associated emotions, may contain people and many objects that may also appear in other photos. Thus, a photo may be linked to many other photos along different dimensions. One may also create explicit links among photos or objects in photos. All these photos on the Web form a Visual Web that links photos with other photos and other information elements. This Visual Web has many new challenges. It also offers opportunities to address new societal issues and solve many difficult yet unsolved problems. In this paper, we will discuss nature of the Visual Web, technical challenges, and some interesting opportunities in this area.
back to keynotes
University of California, Irvine
Ramesh Jain is an entrepreneur, researcher, and educator.
He is a Donald Bren Professor in Information & Computer Sciences at University of California, Irvine where he is doing research in Social Life Networks including EventShop and Objective Self. Earlier he served on faculty of Georgia Tech, University of California at San Diego, The university of Michigan, Ann Arbor, Wayne State University, University of Texas at Austin, University of Hamburg, and Indian Institute of Technology, Kharagpur. He has been an active member of professional community serving in various positions and contributing more than 400 research papers and coauthoring several books. He is the recipient of several awards including the ACM SIGMM Technical Achievement Award 2010. He is a Fellow of ACM, IEEE, AAAI, IAPR, and SPIE.
Ramesh co-founded several companies, managed them in initial stages, and then turned them over to professional management. He also advised major companies in technology areas. His co-founded companies include Imageware (first company that demonstrated concept of 3-D printing in 1995) and a NASDAQ listed company Virage that introduced visual information retrieval. Currently he is involved in founding two companies (FlikStak and SnapViz) and advising more. His research and entrepreneurial interests have been in computer vision, information retrieval, multimedia, social media, and social computing. Understanding and utilizing heterogeneous streams of data for building smart social systems is his current passion.
back to keynotes
Charles Elkan,
University of California, San Diego
In this talk I will discuss examples of how Amazon serves customers and improves efficiency using learning algorithms applied to large-scale datasets. I'll then discuss the Amazon approach to projects in data science, which is based on applying tenets that are beneficial to follow outside the company as well as inside it. Last but not least, I will discuss which learning algorithms tend to be most successful in practice, and I will explain some unsolved issues that arise repeatedly across applications and should be the topic of more research in the academic community. Note: All information in the talk will be already publicly available, and any opinions expressed will be strictly personal.
back to keynotes
University of California, San Diego
Charles Elkan is on leave from being a professor of computer science at the University of California, San Diego, working as Amazon Fellow and leader of the machine learning organization for Amazon in Seattle and Silicon Valley. In the past, he has been a visiting associate professor at Harvard and a researcher at MIT.
His published research has been mainly in machine learning, data science, and computational biology. The MEME algorithm that he developed with Ph.D. students has been used in over 3000 published research projects in biology and computer science. He is fortunate to have had inspiring undergraduate and graduate students who are in leadership positions now such as vice president at Google.
back to keynotes
by David Newman,
Enterprise Architecture and IT Strategy
Wells Fargo
There is increasing awareness within enterprises of the many opportunities becoming available through adoption of emerging technologies and tools that utilize machine intelligence. A transition from reliance on conventional technologies and legacy data stores to more knowledge oriented semantic computing capabilities that make use of natural language processing and text analytics, video analytics, ontologies, reasoners, machine learning, Big Data and graph data stores is beginning to occur. Does this signal the beginning of a major shift in enterprise computing? What are some of these evolving trends and business opportunities? What are some of the major enterprise pain points that semantic computing can help to mitigate? How can enterprises best position themselves for successful deployment of these technologies to maximize business value? How is the financial industry embracing semantic computing?
back to keynotes
Enterprise Architecture and IT Strategy
Wells Fargo
David Newman is Senior Vice President and Strategic Planning Manager of Enterprise Architecture and IT Strategy at Wells Fargo Bank. David chairs the Semantic Technology program for the Enterprise Data Management (EDM) Council and also leads the Council’s Financial Industry Business Ontology (FIBO) effort. FIBO is a collaborative effort by the financial industry to develop ontologies that will provide the next generation of financial data standards. David leads working groups responsible for building various domain ontologies and for developing prototypes that demonstrate FIBO’s operational capabilities. In addition, David is also leading an initiative based on FIBO to provide ontologies that will be published through schema.org that will enable semantic markup of financial content on web sites.
At Wells Fargo, David focuses on identifying and evaluating emerging technologies and trends that will demonstrate value for the enterprise. David is also involved in various R&D and innovation initiatives in the areas of knowledge graphs, customer communications, risk management and regulatory compliance. David leads the Wells Fargo Semantic Technology Community of Interest. David is also interested in the convergence of semantic technologies with text analytics, graph analytics, machine learning and Big Data. David is a frequent speaker at industry conferences on semantic technology, data management, and systemic financial risk. David holds an MBA in Information Systems and an MSW in Psychiatric Social Work.
back to keynotes
by Ching-Yung Lin,
IBM
Cognitive machines are emerging to reason and manage rapidly expanding world of Big Data. Many real-world data are linked. Entities are dependent. Processing, storing, analyzing, retrieving, and visualizing connected data has been a major challenge . Traditional technologies are not equipped to handle these non-uniform, semi-structured, and highly interconnected data. Novel graph computing technologies are being invented and are driving potential paradigm shift.
Graphs may be large or small, static or dynamic, topological or semantic, and property-oriented or Bayesian. Semantic concepts and knowledge as in text, image, video, and audio can be well-represented as graphs. Graphical models have been also showing importance in sequential event understanding and concept reasoning. I am going to discuss Graph Database, High Performance Computing, Middleware, Analytics Library, and Visualization, as well example applications on (1) Cognitive Analytics, which utilizes graphical models to understand and predict people's behavior for Security or Commerce, (2) Social Analytics, which analyzes collective behaviors of people in social media, and (3) Brain Analytics, which models neuron's dynamic networks to understand inner function and correlation. These foundations might be suitable for the progress and future of semantic computing.
back to keynotes
by Anmol Bhasin,
Using Big Data and computing technology to re-imagine the future of the workforce, economic opportunities and flow of capital is a compelling direction of work. Professionals, companies, schools, government units & other public sector organizations complete the set of nodes and digitized explicit & implicit inferred links between them provide for the edges for the digital representation of the physical Economic Graph. This graph facilitates the flow of financial, social and intellectual capital between the nodes. Mining patterns of these capital flows allows for building compelling game changing data products that have the potential to change the future of work.
In this talk, I will present the work done at LinkedIn to first digitize the nodes and edges of the Economic Graph, examples of mining the capital flow and using these building blocks to uncover the tremendous value hidden in plain sight - Finding jobs, recruiting people, facilitating business deals, manage career progressions, bridging the skills gap and peek into numerous other yet unexplored opportunities. We will delve into both the semantic processing of user generated content and metadata on interaction edges as well as applications of Machine Learning and Graph Processing involved in powering these next generation application themes.
back to keynotes
CTO of Adaptive Inc.
Pete Rivett is CTO of Adaptive Inc, a company specializing in the application of metadata and repositories to enterprise modeling and bridging the gap between business and IT. Pete has spent his career in modeling and the development of repository and metadata management software. He works with customers on leading edge projects and is a regular conference speaker.
He is heavily involved in the Object Management Group (OMG), sits on its Board and Architecture Board, and is active in most OMG modeling standards. He is on the Leadership Team for the Financial Industry Business Ontology (FIBO) group and co-chairs the Revision Task Forces for the Meta Object Facility (MOF) and the Ontology Definition Metamodel (ODM), and has a leadership role in the Information Management Metamodel (IMM) and MOF2RDF submissions.
back to keynotes
Linkedln
Anmol Bhasin works as Director of Engineering at LinkedIn. He leads a team of engineers & scientists working on recommender systems, online experimentation and site-personalization. His team's contributions include LinkedIn's various personalized recommendation products (e.g., "Jobs You Might Be Interested In"), social news ("LinkedIn Today"), and systems for ad targeting and click through rate prediction. His work also spans content understanding and canonicalization across various data entities like members, jobs, news articles, ad creatives. In addition, he oversees both statistical and operational aspects of LinkedIn online experimentation (A/B testing) systems.
Prior to LinkedIn, Anmol worked at business search engine Business.com, where he developed the crawler, indexing systems, and retrieval algorithms. Anmol has also authored mobile gaming applications, including the award-winning Tecmo Bowl. Anmol received a Masters in Computer Science from the State University of New York at Buffalo, where he focused on text mining and applied machine learning for cross document learning and applying graph mining approaches for scenario analysis on textual data.
back to keynotes
by Wei Wang,
University of California, Los Angeles
Big data analytics is the process of examining large amounts of data of a variety of types (big data) to uncover hidden patterns, unknown correlations and other useful information. Its revolutionary potential is now universally recognized. Data complexity, heterogeneity, scale, and timeliness make data analysis a clear bottleneck in many biomedical applications, due to the complexity of the patterns and lack of scalability of the underlying algorithms. Advanced machine learning and data mining algorithms are being developed to address one or more challenges listed above. It is typical that the complexity of potential patterns may grow exponentially with respect to the data complexity, and so is the size of the pattern space. To avoid an exhaustive search through the pattern space, machine learning and data mining algorithms usually employ a greedy approach to search for a local optimum in the solution space, or use a branch-and-bound approach to seek optimal solutions, and consequently, are often implemented as iterative or recursive procedures. To improve efficiency, these algorithms often exploit the dependencies between potential patterns to maximize in-memory computation and/or leverage special hardware (such as GPU and FPGA) for acceleration. These lead to strong data dependency, operation dependency, and hardware dependency, and sometimes ad hoc solutions that cannot be generalized to a broader scope. In this talk, I will present some open challenges faced by data scientist in biomedical fields and the current approaches taken to tackle these challenges.
back to keynotes
University of California, Los Angeles
Wei Wang is a professor in the Department of Computer Science at University of California at Los Angeles and the director of the Scalable Analytics Institute (ScAi). She is also a member of the UCLA Jonsson Comprehensive Cancer Center. Dr. Wang received her PhD degree in Computer Science from the University of California at Los Angeles in 1999. She was a professor in Computer Science and a member of the Carolina Center for Genomic Sciences and Lineberger Comprehensive Cancer Center at the University of North Carolina at Chapel Hill from 2002 to 2012, and was a research staff member at the IBM T. J. Watson Research Center between 1999 and 2002. Dr. Wang's research interests include big data, data mining, bioinformatics and computational biology, and databases. She has filed seven patents, and has published one monograph and more than one hundred research papers in international journals and major peer-reviewed conference proceedings.
Dr. Wang received the IBM Invention Achievement Awards in 2000 and 2001. She was the recipient of a UNC Junior Faculty Development Award in 2003 and an NSF Faculty Early Career Development (CAREER) Award in 2005. She was named a Microsoft Research New Faculty Fellow in 2005. She was honored with the 2007 Phillip and Ruth Hettleman Prize for Artistic and Scholarly Achievement at UNC. She was recognized with an IEEE ICDM Outstanding Service Award in 2012 and an Okawa Foundation Research Award in 2013. Dr. Wang has been an associate editor of the IEEE Transactions on Knowledge and Data Engineering, ACM Transactions on Knowledge Discovery in Data, Journal of Knowledge and Information Systems, International Journal of Knowledge Discovery in Bioinformatics, and an editorial board member of the International Journal of Data Mining and Bioinformatics and the Open Artificial Intelligence Journal. She serves on the organization and program committees of international conferences including ACM SIGMOD, ACM SIGKDD, ACM BCB, VLDB, ICDE, EDBT, ACM CIKM, IEEE ICDM, SIAM DM, SSDBM, BIBM.
back to keynotes
by Peter Haug,
Intermountain Healthcare
Electronic Health Records have become an unavoidable part of healthcare in the developed countries. These computerized clinical accounts participate broadly in modern medical practice and influence it in various beneficial ways. An important side effect is the large and growing repository of clinical data captured as a part of the care process. In fact, multiple repositories exist taking the form of data warehouses growing and evolving within advanced care delivery systems. Embedded in these large data collections are key characteristics of patient health and disease as well as the many and varied healthcare delivery workflows and styles practiced in clinics and hospitals around the country.
This data has the ability to inform models of medical decision making that can enrich healthcare delivery. Diagnostic and therapeutic decision support systems can be derived, at least in part from the accumulated data found in these large clinical data repositories. In her lap, we have been exploring semantic approaches that can assist in extracting functioning diagnostic and therapeutic models from these large data stores.
Among the technologies that we have found useful in this context are probabilistic decision support systems informed by ontologies and ontologic principals. In this session, I will describe and discuss the development and use of these systems.
back to keynotes
Intermountain Healthcare
Peter Haug is the Director of the Homer Warner Center for Informatics Research at Intermountain Healthcare and a Professor in the Department of Biomedical Informatics at the University of Utah. He is trained in Medicine (University of Wisconsin) with a postdoctoral fellowship in Biomedical Informatics (University of Utah). Previous experience includes the development of components of two different medical information systems. Current interests include (1) the study of tools for natural language processing in medicine; (2) the evaluation of probabilistic decision support systems for use in the health care process; (3) the development of computer-based tools to deliver detailed medical protocols; and (4) various applications of data mining to assist in the development of innovative medical software. His recently efforts have focused on the construction of environments designed to facilitate applied Informatics research and to support the testing of innovative tools for implementing decision support in active clinical settings.
back to keynotes
by William Hsu,
University of California, Los Angeles
The rate at which biomedical literature is being published is quickly outpacing our ability to effectively leverage this information for evidence-based medicine. While papers are readily searchable through databases such as PubMed, clinicians are often left with the time-consuming task of finding, assessing, interpreting, and applying this information. Tools that structure evidence from published papers using a standardized data model and provide an intuitive query interface for exploring documented biomedical entities would be valuable in utilizing this information as part of the clinical decision making process. This talk presents efforts towards developing computational tools and a representation for modeling and relating evidence from multiple clinical trial reports for lung cancer. Challenges related to representing this information in a machine-interpretable manner, assessing study quality, and handling conflicting evidence are described. I discuss the development of two tools: 1) an annotator tool used to extract information from papers, mapping it to concepts in an ontology-based representation and 2) a visualization that summarizes information about a single paper based on information captured in the model. Using lung cancer as a driving example, I demonstrate how these tools help users apply information reported in literature towards individually tailored medicine.
back to keynotes
University of California, Los Angeles
William Hsu is an Assistant Professor with the UCLA Medical Imaging Informatics Group in the Department of Radiological Sciences. He received his Ph.D. in Biomedical Engineering with an emphasis in Medical Imaging Informatics from the University of California, Los Angeles in 2009 and a BS degree in Biomedical Engineering from Johns Hopkins University in 2004. His research interests include medical data visualization, disease modeling, knowledge representation, and imaging informatics. He was recently awarded a grant from the American College of Radiology and serves on the advisory board of the American Medical Informatics Association's Biomedical Imaging Informatics Working Group.
back to keynotes
by Satya Sahoo,
Case Western Reserve University
Healthcare datasets are increasingly characterized by large volume, high rate of generation as well as need for real time analysis (velocity), and variety. These datasets are often termed biomedical big data and include multi-modal electrophysiological signals that record different aspects of human body. In this talk, we focus on the computational challenges associated with signal data management and the role of semantic computing in addressing these challenges. We use the term semantic computing to describe formal knowledge models or ontologies that capture complex domain semantics and multiple components of the Semantic Web technology stack, such as Web Ontology Language (OWL).
We describe a cloud computing platform called Cloudwave that has been developed to effectively manage electrophysiological big data for epilepsy clinical research and patient care. The Cloudwave platform consists of (a) an Ontology-driven Web-based signal visualization and query module, (b) a data processing and storage module that extends the Hadoop Distributed File System (HDFS), and (c) a dedicated middleware layer to efficiently retrieve and transfer data from storage to visualization module. An epilepsy domain ontology plays a central role in Cloudwave by using domain semantics to underpin multiple functionalities.
back to keynotes
Case Western Reserve University
Satya Sahoo is faculty in the Division of Medical Informatics and EECS department at the Case Western Reserve University (CWRU). Satya's research focuses on Semantic Web informatics including: (1) ontology engineering (upper-level reference ontologies to application/domain-specific ontologies), (2) ontology- driven data integration and query optimization, and (3) provenance metadata management. His current research projects include the development of cloud-based "Big data" application for clinical research (Cloudwave), Ontology-driven patient information capture (OPIC), and clinical text interpretation (EpiDEA) using Natural Language Processing (NLP). Prior to joining CWRU, he completed research internships at the National Library of Medicine and Microsoft Research. Satya has served as member of W3C working group to define the new provenance standard called PROV.
Additional information about his research projects is available at: Link
back to keynotes
by Tanveer Syeda-Mahmood, Ph.D,
IBM Research - Almaden
Diagnostic decision support is still very much an art for physicians in their practices today due to lack of scalable quantitative tools. We have been pioneering a scalable approach to clinical decision support that exploits the consensus opinions of other physicians who have looked at similar patients. Unlike previous rule-based decision support systems, this is a data mining approach exploiting the vast amount of patient data and prior diagnosis recorded in medical record systems. The key idea is to find similarity in patient's clinical data modalities in order to infer similarity in patients. Collaborative filtering is then used to obtain a ranked distribution of associated diagnosis, treatment and outcome. Sophisticated medical image analysis, feature extraction, machine learning and search techniques have been developed to find similar patients based on a disease specific analysis of their heart sounds, EKGs, echocardiograms and coronary angiograms in the domain of cardiology. The talk will give an overview of patient similarity technology and describe its evolution over the years from research to healthcare informatics products and solutions.
back to keynotes
SemIBM Almaden
Dr. Tanveer Syeda-Mahmood is the Chief Scientist and Senior Manager leading the global IBM Research-wide Medical Sieve Radiology Grand Challenge project. The goal of this project is to advance IBM Watson for imaging by developing automated radiology and cardiology assistants of the future that help clinicians in their decision making.
Dr. Syeda-Mahmood graduated from the MIT AI Lab in 1993 with a Ph.D in Computer Science. Prior to IBM in 1998, she worked as a Research Staff Member at Xerox Webster Research Center, Webster, NY. Dr. Syeda-Mahmood led the image indexing program at Xerox Research and later at IBM QBIC, and was one of the early originators of the field of content-based image and video retrieval. Currently, she is working on applications of content-based retrieval in healthcare and medical imaging. Over the past 30 years, her research interests have been in a variety of areas relating to artificial intelligence including computer vision, image and video databases, medical image analysis, bioinformatics, signal processing, document analysis, and distributed computing frameworks. She has over 200 refereed publications and over 80 filed patents.
Dr. Syeda-Mahmood was the General Chair of the First IEEE International Conference on Healthcare Informatics, Imaging,and Systems Biology, San Jose, CA 2011. She was also the program co-chair of IEEE CVPR 2008. Dr. Syeda-Mahmood is a Fellow of IEEE. She is also a member of IBM Academy of Technology. Dr. Syeda-Mahmood was declared Master Inventor in 2011.
back to keynotes
Professor
University of Texas, Dallas
Dr. Bhavani Thuraisingham is the Louis A. Beecherl, Jr. I Distinguished Professor in the Erik Jonsson School of Engineering and Computer Science at the University of Texas at Dallas (UTD) effective September 2010. She joined UTD in October 2004 as a Professor of Computer Science and Director of the Cyber Security Research Center which conducts research in data security and privacy, secure networks, secure languages, secure social media, data mining and semantic web. She is an elected Fellow of three prestigious organizations: the IEEE (Institute for Electrical and Electronics Engineers), the AAAS (American Association for the Advancement of Science) and the BCS (British Computer Society). She is the recipient of numerous awards including the IEEE Computer Society’s 1997 Technical Achievement Award for “outstanding and innovative contributions to secure data management” and the 2010 Research Leadership Award for Outstanding and Sustained Leadership Contributions to the field of Intelligence and Security Informatics” presented jointly by the IEEE Intelligent and Transportation Systems Society Technical Committee on Intelligence and Security Informatics in Transportation Systems and the IEEE Systems, Man and Cybernetics Society Technical Committee on Homeland Security. She served as served as an IEEE Distinguished Lecturer between 2002 and 2005. She was also quoted by Silicon India magazine as one of the seven leading technology innovators of South Asian origin in the USA in 2002.
back to keynotes
by Giovanni Tummarello
SindiceTech
Google, Facebook, Yahoo and others have long announced "Knowledge Graph" effort by which information surrounding any aspect of their user experience is connected around a "backbone" of highly structured yet highly flexible semantic information. Outside the world of web giants, the same capabilities would be highly strategic in sectors like life sciences, to finance, technical publishing, defense and more. But is the technology accessible to those that don't have a web giant R&D budget? In this talk, i will discuss what it takes to create a "enterprise knowledge graph" and how a pragmatic combination of "classic" big data processing and techniques that were specifically developed to address the "web of data" or "semantic web" can be used to processing, search and browse thus mastering an data scenario novel for its amount and diversity of data.
back to keynotes
CEO of SindiceTech
Giovanni Tummarllo, Ph.D is a well known figure in world of Semantic Web and linked data for a number of influential projects among which Sindice.com - a specialized search engine for the Web of Data referred to by over 1000 scholarly works, Sig.ma
Her early experiences in industry with the development of hypertext authoring tools inspired her towards underlying questions of combining time-dependent documents (such as video sequences) along with interaction through links into a single model. She was a member of the W3C working group that developed the first SMIL recommendation.
Since the development of the semantic web, she has dedicated herself to improving human access to the ever-expanding 'linked data cloud'. Her current research efforts are focused on improving design methods for human-based interfaces in relation to developing technology.
She is a member of the editorial board for the Journal of Web Semantics, and the New Review of Hypermedia and Multimedia, and was co-programme chair for SAMT 2008 and ACM Hypertext 2003.
back to keynotes

Foto Jeroen Oerlemans
by Roger B. Dannenberg
School of Computer Science, Art, and Music
Carnegie Mellon University
Music understanding is the automatic recognition of pattern and structure in music. Music understanding problems include matching, searching, and parsing problems related to music recognition and music classification. Music semantics is a more difficult subject. Music, like abstract art, rarely denotes anything specific, and one can argue that music semantics is an oxymoron. Nevertheless, music can be associated with emotions and many other terms or tags, leading to representations similar to those used for semantic computation in other domains. We are at a time of music revolution where old practices of publishing and recording are being challenged by new technologies and consumer expectations. I believe this revolution will continue with the advance of music computation, which will enable new forms of music practice. Music understanding and semantic computing will play an important role in the future of music.
back to keynotes
Herbert A. Simon Professor
Computer Science Department
Carnegie Mellon University
Manuela M. Veloso is Herbert A. Simon Professor of Computer Science at Carnegie Mellon University. She directs the CORAL research laboratory, for the study of agents that Collaborate, Observe, Reason, Act, and Learn, www.cs.cmu.edu/~coral. Professor Veloso is a Fellow of the Association for the Advancement of Artificial Intelligence, and the President of the RoboCup Federation. She recently received the 2009 ACM/SIGART Autonomous Agents Research Award for her contributions to agents in uncertain and dynamic environments, including distributed robot localization and world modeling, strategy selection in multiagent systems in the presence of adversaries, and robot learning from demonstration. Professor Veloso is the author of one book on "Planning by Analogical Reasoning" and editor of several other books. She is also an author in over 200 journal articles and conference papers.
back to keynotes
Associate Professor
Biomedical Informatics at the University of Pittsburgh School of Medicine
Director of the Pittsburgh Graduate Training Program in Biomedical Informatics
Rebecca Crowley is an Associate Professor of Biomedical Informatics at the University of Pittsburgh School of Medicine and Director of the Pittsburgh Graduate Training Program in Biomedical Informatics. She received her MD and MS in Information Science from the University of Pittsburgh, and her post-graduate training in Pathology and Neuropathology at Stanford University. Dr. Crowley was a National Library of Medicine (NLM) Fellow in Biomedical Informatics, and a Howard Hughes Medical Institute Fellow in Molecular Neuroendocrinology. Her research interests include applications of semantic technologies to clinical teaching and translational biomedical research as well as the sociotechnical requirements and consequences of sharing biomedical data. Dr. Crowley has also contributed to several large scale biomedical data sharing consortia focused on semantic interoperability including the Cancer Biomedical Informatics Grid (caBIG).
back to keynotes
Associate Research Professor
School of Computer Science, Art, and Music
Carnegie Mellon University
Dr. Roger B. Dannenberg is an Associate Research Professor in the Schools of Computer Science, Art, and Music at Carnegie Mellon University, where he is also a fellow of the Studio for Creative Inquiry. Dannenberg is well known for his computer music research, especially in real-time interactive systems. His pioneering work in computer accompaniment led to three patents and the SmartMusic system now used by tens of thousands of music students. He also played a central role in the development of the Piano Tutor, an intelligent, interactive, automated multimedia tutor that enables a student to obtain first-year piano proficiency in less than 20 hours. Dannenberg held a patent for large-scale interactive games controlled by crowd noise, and these "stadium games" have entertained many NFL fans. Other innovations include the application of machine learning to music style classification and the automation of music structure analysis. As a trumpet player, he has performed in concert halls ranging from the historic Apollo Theater in Harlem to the Espace de Projection at IRCAM, and he is active in performing jazz, classical, and new works. His compositions have been performed by the Pittsburgh New Music Ensemble, the Pittsburgh Symphony, and at festivals such as the Foro de Musica Nueva, Callejon del Ruido, Spring in Havana, and the International Computer Music Conference.
back to keynotes
David Ostrowski works at the Ford Research and Innovation Center as a Technical Expert in Data Mining and Machine Learning concentrating in the area of Social Media Analytics. Dr. Ostrowski holds a Doctorate in Computer Science from Wayne State University and has over 27 years of industry experience in software development within many areas including real-time data acquisition and analytics. He has 15 years of experience teaching CIS curriculums at the undergraduate and graduate levels. Dr. Ostrowski also has over 40 refereed publications, two book chapters, numerous technical reports, and participates within several technical committees including IEEE TEC transactions, IEEE ICSC and IEEE ICIOS.
back to keynotes

by David A. Ostrowski
Ford Research and Innovation Center
This tutorial will specifically step each student though the installation, setup and implementation of Hadoop architecture on Amazon Web Services. Included topics are the HIVE and PIG query languages, HDFS file system as well as the Apache Mahout Machine Learning package. Additional Hadoop-based techniques / frameworks will be explored including custom Map Reduce programming relying on Hadoop Streaming I/O and the Python programming language as well as Apache Spark and Shark relying on the Scala Programming language. Overall architecture design will also be explored as well as the future direction of the Big Data software suite. Bring your laptop and amazon account to engage in hands-on examples leaving with experience in all mentioned technologies.
back to keynotes
Industry Session Call for Papers
IEEE ICSC 2015: The Eighth IEEE International Conference on Semantic Computing
September 16-18, 2013
Irvine, CA
Program Goals and Format:
The goals of the ICSC 2015 Industry Session are to foster exchanges
between practitioners and the academics, to promote novel solutions to
today's challenges in the area of Semantic Computing and applications, to
provide practitioners in the field an early opportunity to evaluate
leading-edge research, and to identify new issues and directions for
future research and development efforts. Similar to regular papers, the
papers in the industry session will undergo a review process and will
appear in the conference proceedings. However, the selection criteria for
industry papers are slightly different. In particular, papers should
describe technologies, methodologies, applications, prototypes or
experiences of clear industry relevance. A main goal of this session is to
present research work that exposes the academic and research communities
to challenges and issues important for the industry. Therefore, the papers
in this session will be evaluated primarily by the novelty and
applicability of the insights from its industrial solutions, instead of
the originality of its algorithmic content.
Topics of Interest:
Topics of particular interest include but are not limited to those
identified in the main conference CFP, as well as those listed below:
1. Development of new semantic systems, architecture, and standards
2. Employment of semantic computing tools and interfaces
3. Employment of large-scale semantic systems
4. Benchmarking and performance evaluation of semantic systems
5. Innovative solutions for performance optimization
6. Mobile semantic systems and services
7. Multimedia semantic content analysis and retrieval systems
8. Modeling issues and case studies of semantic computing
9. Game and entertainment applications
10. e-Business and other applications
11. Analysis of industry-specific trends and challenges
Important Dates:
Submission: June 10, 2013
Notification: June 28, 2013
Conference: September 16-18, 2013
Industrial Paper Submission:
Industrial papers should be submitted via the ICSC 2015 online paper
submission system. Industry Session papers should be no longer than 8
pages with the same submission guidelines available on the ICSC 2015 web
page. Only electronic submission will be accepted. All industrial papers
will be peer-reviewed and published in the conference proceedings, which
will be published by the IEEE Computer Society Press. Submissions must not
be published or submitted for another conference.
Industry Session Co-Chairs:
Abha Moitra, GE Research, USA
David Ostrowski, Ford, USA
-------------------------------------------------------------
Note:
1. Every paper accepted for publication in the Proceedings of ICSC 2015
MUST be presented during the conference.
2. Every paper accepted for ICSC 2015 MUST have attached to it at least
one registration at the full member/nonmember rate. Thus, for a paper for
which all authors are students, one student author will be required to
register at the full registration rate.
Sören Auer, Universität Leipzig
Agnese Augello, ICAR - Istituto di Calcolo e Reti ad alte prestazioni Consiglio Nazionale delle Ricerche
Lamberto Ballan, University of Florence
Roberto Basili, Dept. of Enterprise Engineering - Univ. of Roma Tor Vergata
Ivan Bedini, Trento Rise
Marco Bertini, Universita' degli Studi di Firenze
Michael Bloodgood, University of Maryland
David Bracewell, Language Computer Corporation
Volha Bryl, University of Mannheim
Xiao Cai, University of Texas at Arlington
Nicoletta Calzolari, Istituto di Linguistica Computazionale - CNR
Chao Chen, University of Miami
Matthew Cooper, FX Palo Alto Lab, Inc.
Jason Corso, SUNY at Buffalo
Claudia D'Amato, University of Bari
Ernesto D'Avanzo, Università degli Studi di Salerno
Nicola Fanizzi, Dipartimento di Informatica, Università di Bari
Gerald Friedland, ICSI
Luigi Gallo, ICAR-CNR
Jose Manuel Gomez-Perez, Intelligent Software Components (iSOCO) S.A.
Thomas Gottron, University of Koblenz-Landau
William Grosky, University of Michigan
Choochart Haruechaiyasak, National Electronics and Computer Technology Center (NECTEC)
Takako Hashimoto, Chiba University of Commerce
Johannes Heinecke, France Telecom
Jingshan Huang, University of South Alabama
Eero Hyvönen, Aalto University and University of Helsinki
Yexi Jiang, Florida International University
Artem Katasonov, VTT Technical Research Centre of Finland
Doo Soon Kim, Accenture Technology Lab
Tracy Holloway King, eBay
Ruediger Klein, Fraunhofer IAIS
Lars Knipping, Berlin Institute of Technology
Yiannis Kompatsiaris, CERTH - ITI
Deguang Kong, Penn State University
Shuichi Kurabayashi, Keio University
Marco La Cascia, University of Palermo
Freddy Lecue, IBM Research
Ying Li, IBM Research
Lei Li, Florida International University
Chen Lin, Xiamen University
Hongli Luo, Indiana University - Purdue University Fort Wayne
Umberto Maniscalco, CNR
Elio Masciari, ICAR-CNR
Dennis Mcleod, University of Southern California
Marjorie Mcshane, Rensselaer Polytechnic Institute
Robert Mertens, Fraunhofer IAIS
Farid Meziane, University of Salford
Fionn Murtagh, De Montfort University
Shinichi Nagano, Toshiba Corporation
Ming Ni, Nanjing University of Science and Technology
Feiping Nie, University of Texas, Arlington
Nick Pendar, Uptake Networks
Giovanni Pilato, ICAR-CNR
Roberto Pirrone, Università degli Studi di Palermo
Luigi Pontieri, ICAR, National Research Council of Italy (CNR), Italy
Alessandro Provetti, Dept. of Mathematics and Informatics, Univ. of Messina
Matthew Purver, Queen Mary University of London
Marco Rospocher, Fondazione Bruno Kessler
Irene Russo, Istituto di Linguistica Computazionale - CNR Pisa
Harald Sack, Hasso-Plattner-Institute for IT Systems Engineering, University of Potsdam
Alkis Simitsis, HP Labs
Nadine Steinmetz, Hasso Plattner Institute for Software Systems Engineering
Liang Tang, Linkedin
Matthias Thimm, Universität Koblenz-Landau
Marc Tomlinson, Language Computer
Marc Verhagen, Brandeis University
Dingding Wang, Florida Atlantic University
René Witte, Concordia University
Bin Xia, Nanjing University of Science and Technology
Fan Yang, Xiamen university
Qifeng Zhou, Xiamen University
Jiayu Zhou, Samsung Research America
Xingquan Zhu, Florida Atlantic University
Ziming Zhuang, Tencent Inc.
Roger Zimmermann, National University of Singapore
Anhheim Marriott is now taking reservations for ICSC 2015 at a discounted room rate!
Reserve your room at the Anhheim Marriott while space is still available!
Please make your reservation online here: ICSC2015 GROUP RATE RESERVATION.
Or you may call their number: 877.622.3056, and mention "ICSC 2015".
Call for Demonstration
IEEE ICSC 2015: The 8th IEEE International Conference on Semantic Computing
September 16-18, 2013
Irvine, CA
The IEEE ICSC 2015 organizing committee invites proposals for
demonstrations to be given at the conference. The demonstrations provide a
forum for researchers as well as industry participants to demonstrate
working systems, applications, tools or showcases of base technologies to
the conference attendees. The goal of the demonstrations is to show a
spectrum ranging from research prototypes to pilots developed and even
products that use semantic technology and provide functionality based on
semantics in the context of semantic computing. For submissions to this
event, it is very important to describe the demonstration setup,
functionality and benefit to the viewer of the demonstration. Technical
background discussion can be presented at the actual demonstration or can
be submitted as an industry track or regular conference paper; the focus
of the demonstration themselves should be to show the functionality to
viewers. It is expected that the demonstrations are highly interactive.
Topics for demonstrations include but are not limited to:
* Content and Information Management
* Knowledge Engineering
* Data Mining
* Semantic Database Theory and Systems
* Service-oriented Architectures and Computing
* Semantic Web and Semantic Web Services
* Multimedia Semantics
* Audio and Speech Processing
* Natural Language Processing
* Semantic Search Technologies and Applications
* User Interfaces
Demonstrations are ideally demonstrating a system or application that
clearly shows the benefit of using and deploying semantics and semantic
technologies. In addition, tools and base technologies that implement or
use semantic technology or semantic approaches are invited for
demonstration.
Demonstration Setup
The demonstrations are planned to be a single event during a conference
reception function, open to all conference attendees, with the goal of
open and constructive discussions. One table will be provided with power
as well as an Internet connection. Posters can be put up behind or next to
the tables (depending on the space) either on pin boards or the wall.
Demonstrators must bring any additional equipment they require as no
equipment will be provided by the conference.
Demonstration Submissions
Authors submitting papers to the demonstrations must submit a 2-page paper
that clearly outlines the demonstration that will be set up and the
functionality a visitor to the demonstration can observe. The technical
background, such as the architecture or algorithms, should not be
described in detail; such a description would be better submitted to the
industry track or main conference paper track. Including links to
supporting material, e.g. a video on the web or a web-based demo itself,
is highly encouraged. All submissions must be in double-column IEEE format
and follow the specific submission guidelines on the ICSC2012 web page.
The Conference Proceedings will be published by the IEEE Computer Society
Press and the accepted demonstration submissions will be included in the
conference proceedings.
Important Dates
Demo Submission: June 10, 2013
Notification: June 28, 2013
Conference: September 16-18, 2013
Submissions
Researchers and practitioners are invited to submit demo proposals to the
demo co-chair
Please include "[ICSC2013-DEMO]" in the subject of your emails.
Call for Applications
2nd International Summer School on Semantic Computing
July 25-31, 2010
University of California, Berkeley
co-sponsored by IEEE, Institute of Semantic Computing and STI International
Semantic Computing is currently emerging as a new field that integrates methods from multimedia (computer vision, speech processing), natural language processing, semantic web and ontology engineering, software engineering, and other fields with the goal of creating new applications that connect intuitively formulated user-intentions with the content of data.
The summer school will provide an introduction to the field to senior undergraduate and graduate students. A mix of young and well-established researchers and educators will present recent research results, as for example presented in the IEEE conferences on Semantic Computing. The tutorials will be complemented by keynote talks by renowned experts in the areas of Semantic Technologies, Ontologies, Multimedia or Natural Language Processing.
The 6-day event is taking place on the campus of the University of California, Berkeley and the curriculum will include the following topics:
- Formal Semantics
- Semantic Web
- Ontology Engineering
- Multimedia
- Natural Language Processing
Important Dates:
* May, 1: Application deadline
* May, 15: Notification of acceptance/Registration opens
* June, 15: Registration completed
* July, 25: School starts
For instruction on how to apply and other information, please
visit the following website: http://sssc2010.org
Manuscripts must be written in English and follow the instructions in the Manuscript Formatting and Templates page
Document templates are located at:
Regular Papers should be no longer than eight (8) pages, Short Papers should be no longer than four (4) pages, Demonstration Papers and Posters should be no longer than two (2) pages.
All paper submissions will be carefully reviewed by at least three experts and reviews will be returned to the author(s) with comments to ensure the high quality of the accepted papers. The authors of accepted papers must guarantee that their paper will be presented at the conference. Please only submit original material where copyright of all parts is owned by the authors declared and which is not currently under review elsewhere. Please see the IEEE policies for further information.
Technical Paper Submission Instructions
Only electronic submission will be accepted. Technical paper authors MUST submit their manuscripts through EasyChair. Please follow this link (please register if not an EasyChair user). Manuscripts may only be submitted in PDF format.
A copyright form needs to be submitted upon acceptance of the paper and is not required at this stage.
Note:
1. Every paper accepted for publication in the Proceedings of ICSC 2015 MUST be presented during the conference.
2. Every paper accepted for ICSC 2015 MUST have attached to it at least one registration at the full member/nonmember rate. Thus, for a paper for which all authors are students, one student author will be required to register at the full registration rate.
The registration deadline is January 16 for authors and January 23 for general participants.
The registration fee is $650 for IEEE-member, $790 for Non-IEEE member, and $300 for student.
If you register after the deadline, then the fee will become $790 for IEEE-member, $950 for Non-IEEE member, and $430 for student.
At least one author each paper has to pay a full registration.
Each extra page for your paper is $200.
If you have more than one paper accepted, each extra paper is $450.
We accept online credit card payment. Please access Online Registration System to register.
If you are not in U.S., you might need to ask your credit card bank first to allow foreign transaction.
Please print out the receipt after you pay online, we will not provide a physical copy on-site.
Email any question regarding registration to Shao-Ting Wang at shaotinw@uci.edu
Those who need to apply for Visa, please send an email to Prof. Chengcui Zhang zhang@cis.uab.edu as follows:
* In the subject line write "Visa Letter for IEEE ICSC 2015"
* Provide the full title of the paper including the author list and affiliation and the name of the presenter seeking the letter for Visa.
* Make sure to register for the conference. If you are not the author, you will need to provide the online receipt of your payment for registration.
Your final papers MUST be formatted to IEEE Computer Society Proceedings Manuscript Formatting Guidelines (see the following link below). It is highly recommended that you proofread and check the layout of your paper BEFORE submitting
Document templates are located at:
Regular Papers should be no longer than eight (8) pages, Short Papers should be no longer than four (4) pages, Demonstration Papers and Posters should be no longer than two (2) pages.
Please submit your camera-ready paper through EasyChair. Please follow this link. It may only be submitted in PDF format.
A copyright form is also need to be submitted. Please follow this link.
Note:
1. Every paper accepted for publication in the Proceedings of ICSC 2015 MUST be presented during the conference.
2. Every paper accepted for ICSC 2015 MUST have attached to it at least one registration at the full member/nonmember rate. Thus, for a paper for which all authors are students, one student author will be required to register at the full registration rate.
Failure to do so will result in removal of your paper from the conference proceedings.
- December 31, 2014: Deadline for Camera-ready and Copyright Form Submissions
© IEEE-ICSC 2015